First example: TGF-beta dataset
TGFB.RmdOverview
We will follow the 3-steps workflow of the condiments package:
- We start by integrating datasets from multiple conditions and then check if we can fit a single trajectory, which we call differential topology.
- By comparing the conditions along the trajectory’s path, we can detect large-scale changes, indicative of differential progression.
- We also demonstrate how to detect subtler changes by finding genes that exhibit different behaviors between these conditions along a differentiation path, commonly known as differential expression.
suppressPackageStartupMessages({
library(slingshot); library(SingleCellExperiment)
library(dplyr); library(condiments);
library(RColorBrewer); library(scales)
library(viridis); library(UpSetR)
library(pheatmap); library(msigdbr)
library(fgsea); library(knitr)
library(ggplot2); library(gridExtra)
library(tradeSeq); library(cowplot)
})
theme_set(theme_classic())Analysis
Dataset
The dataset we will be working with concerns a single-cell RNA-sequencing dataset consisting of two different experiments, which correspond to two treatments. McFaline-Figueroa et al. studied the epithelial-to-mesenchymal transition (EMT), where cells spatially migrate from the epithelium to the mesenchyme during development. This process will be described by a trajectory, reflecting the gene expression changes occurring during this migration. The authors furthermore studied both a control (Mock) condition, and a condition under activation of transforming growth factor \(\beta\) (TGFB).
In summary, we will be investigating a trajectory consisting of a single lineage that represents the EMT. This lineage is studied in two different conditions; a control condition and a TGFB-induced condition.
Integration
Our dataset contains cells collected from samples undergoing two different treatment conditions which were necessarily collected separately. Hence, we will start with an integration step to combine these two sets of cells, similar to batch correction. Our goal is to remove the technical effects of the different sample collections while preserving any true, biological differences between the two treatment groups.
Data integration and normalization are complex problems and there are a variety of methods addressing each. Interested participants can explore the corresponding chapter of the Bioconductor Ebook. However, since neither is the main focus of this workshop, we elected to use an existing pipeline for these tasks. The full Seurat data integration workflow with SCTransform normalization is described in this vignette.
Since this whole step is quite slow, it will not be run during the workshop but the code is provided below, along with a function to download and preprocess the public data from GEO.
tgfb <- bioc2021trajectories::import_TGFB()
########################
### Split by condition and convert to Seurat
########################
assays(tgfb)$logcounts <- log1p(assays(tgfb)$counts)
tgfbMock <- tgfb[, tgfb$treatment_id == 'Mock']
tgfbTGFB <- tgfb[, tgfb$treatment_id == 'TGFB']
library(Seurat)
soMock <- as.Seurat(tgfbMock)
soTGFB <- as.Seurat(tgfbTGFB)
########################
### Normalize
########################
soMock <- SCTransform(soMock, verbose = FALSE)
soTGFB <- SCTransform(soTGFB, verbose = FALSE)
########################
### Integrate
########################
dtlist <- list(Mock = soMock, TGFB = soTGFB)
intfts <- SelectIntegrationFeatures(object.list = dtlist, nfeatures = nrow(tgfb)) # maxes out at 4080 (why?)
dtlist <- PrepSCTIntegration(object.list = dtlist,
anchor.features = intfts)
anchors <- FindIntegrationAnchors(object.list = dtlist, normalization.method = "SCT",
anchor.features = intfts)
integrated <- IntegrateData(anchorset = anchors, normalization.method = "SCT")
integrated <- RunPCA(integrated)
integrated <- RunUMAP(integrated, dims = 1:50)
## convert back to singleCellExperiment
tgfb <- as.SingleCellExperiment(integrated, assay = "RNA")
tgfb <- tgfb[, sample(ncol(tgfb))]Import dataset
We have made the pre-processed, integrated dataset available as a SingleCellExperiment object in the workshop package, which we import below.
data("tgfb", package = "bioc2021trajectories")Exploration
Once the two datasets have been integrated, we can visualize all the single cells in a shared reduced dimensional space.
We also visualize the distribution of cells in this space according to the treatment (control and TGFB) and spatial location (inner cells versus outer cells).
df <- bind_cols(
as.data.frame(reducedDims(tgfb)$UMAP),
as.data.frame(colData(tgfb)[, !colnames(colData(tgfb)) == "slingshot"])
)
ggplot(df, aes(x = UMAP_1, y = UMAP_2, col = treatment_id)) +
geom_point(size = .7) +
scale_color_brewer(palette = "Accent") +
labs(col = "Treatment")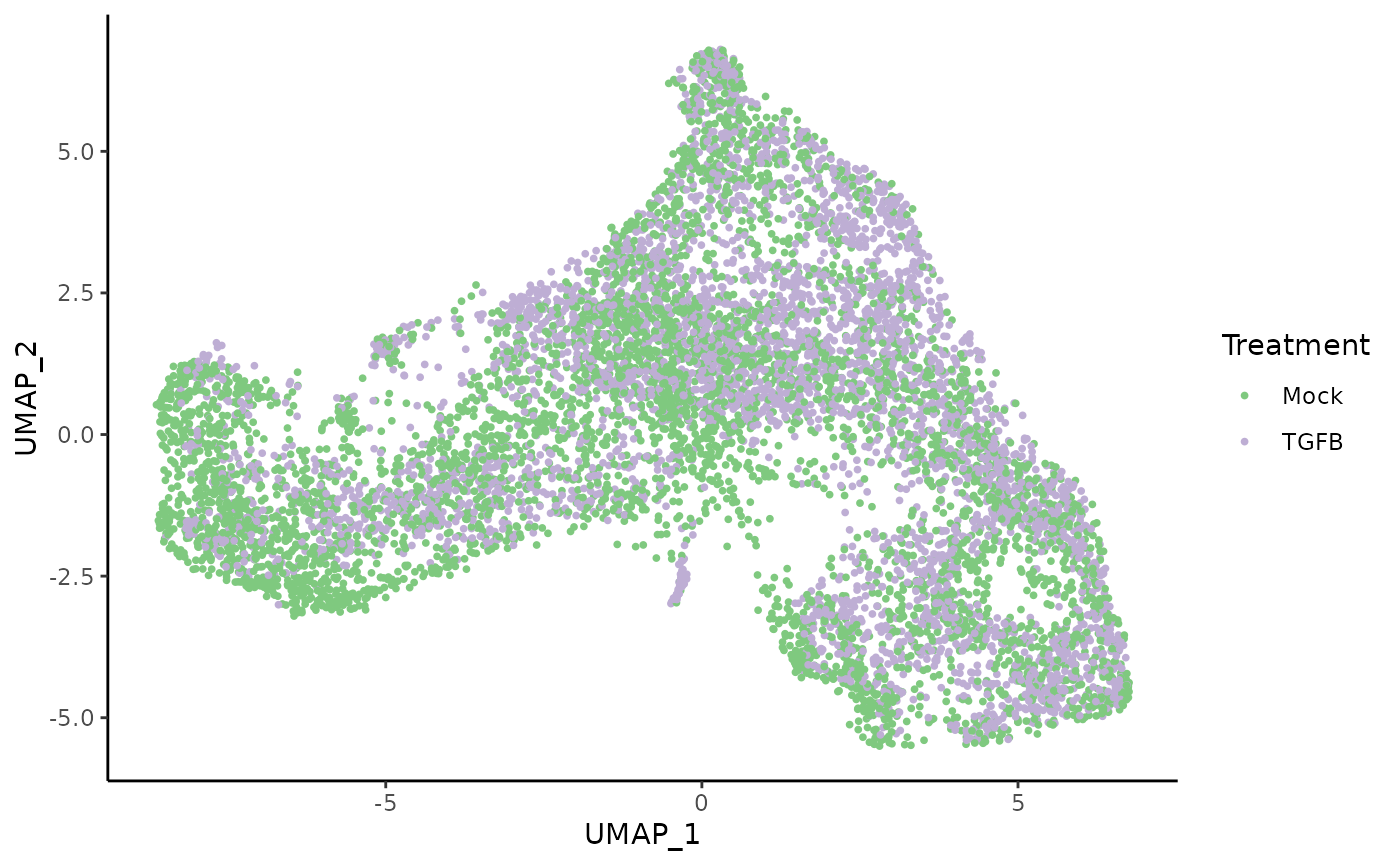
ggplot(df, aes(x = UMAP_1, y = UMAP_2, col = spatial_id)) +
geom_point(size = .7) +
scale_color_brewer(palette = "Dark2") +
labs(col = "Spatial ID")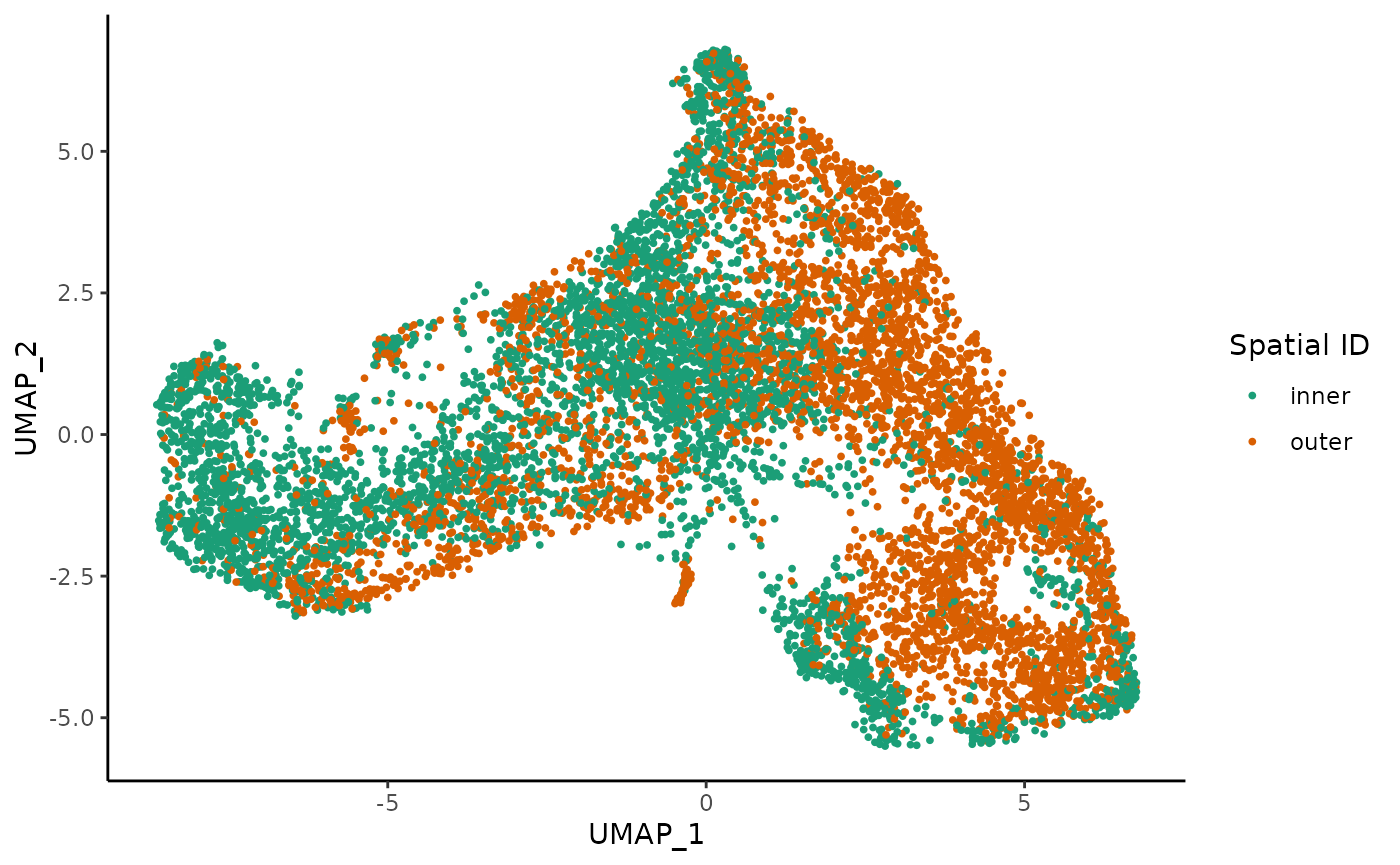
We know from biological knowledge that the EMT development goes from the inner to the outer cells. The question is: should we fit a separate trajectory for each condition? We might expect the trajectory itself to be changed by the treatment if the treatment effect is systematically large. Otherwise, the treatment may impact the expression profile of some genes but the overall trajectory will be preserved.
To help assess this, we devised an imbalance score. Regions with a high score indicate that the local cell distribution according to treatment label is unbalanced compared the overall distribution. Here, we see that, while there are some small regions of imbalance, the global path along the development axis is well-balanced. This means that we should be able to fit a global trajectory to the full dataset.
library(condiments)
tgfb <- condiments::imbalance_score(tgfb, conditions = tgfb$treatment_id,
k = 20, smooth = 40, dimred = "UMAP")
df$scores <- tgfb$scores$scaled_scores
ggplot(df, aes(x = UMAP_1, y = UMAP_2, col = scores)) +
geom_point(size = .7) +
scale_color_viridis_c(option = "C") +
labs(col = "Scores")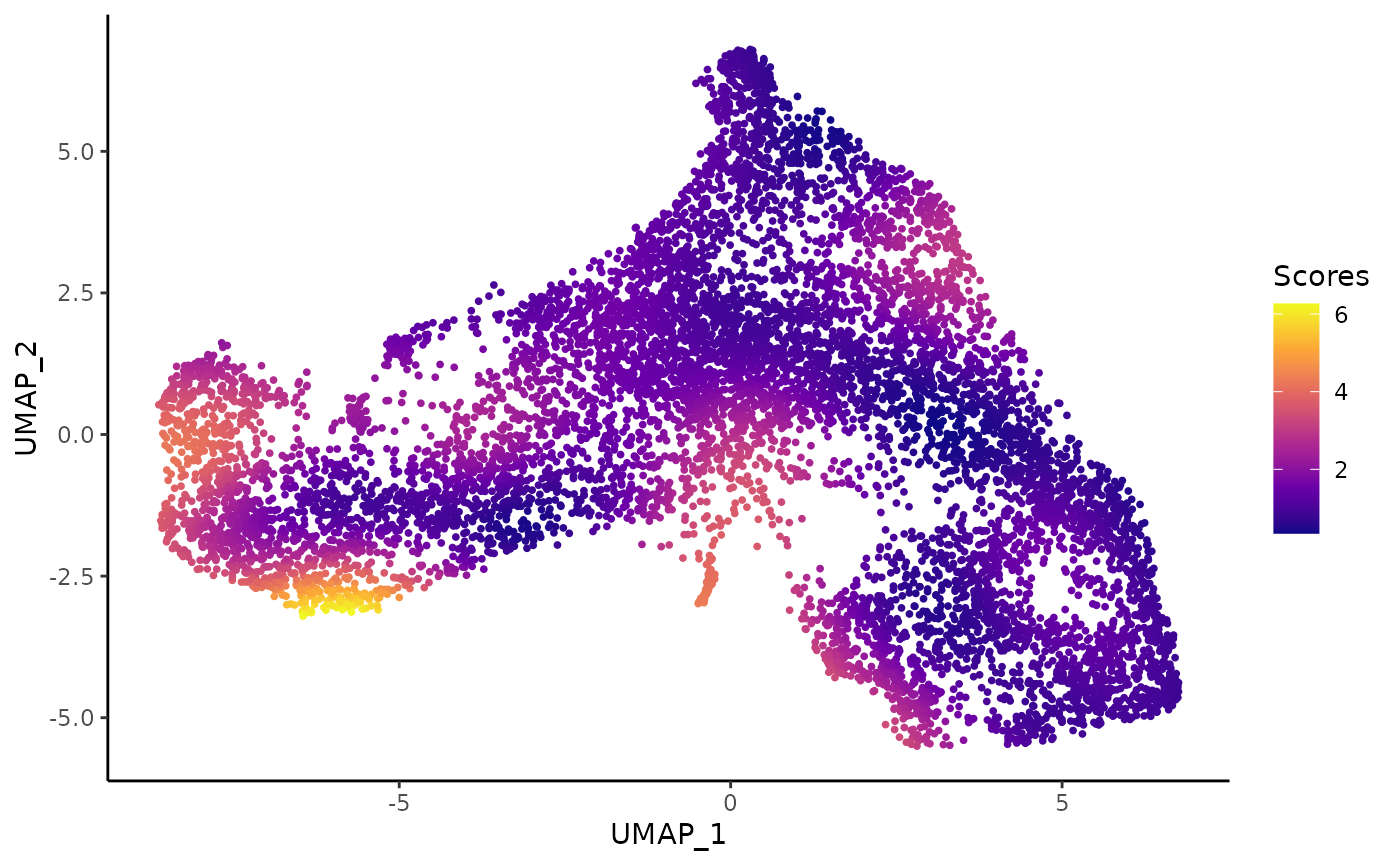
For more information on the score, run help("imbalance_score", "condiments")
We can also rely on a more principled approach, using the topologyTest.
Differential Topology and Trajectory Inference
We perform trajectory inference to order the cells according to EMT progression. We use slingshot for trajectory inference, with the cells’ position (inner or outer) serving as the cluster identifier. This ensures that we will only find a single lineage while still allowing sufficient flexibility to correctly orient the pseudotime axis. We first fit a common trajectory to extract the skeleton.
library(slingshot)
tgfb <- slingshot(tgfb, reducedDim = 'UMAP', clusterLabels = tgfb$spatial_id,
start.clus = 'inner', approx_points = 150)
# tgfb@int_metadata$slingshot <- tgfb$slingshot
mst <- slingMST(tgfb, as.df = TRUE)
ggplot(df, aes(x = UMAP_1, y = UMAP_2, col = spatial_id)) +
geom_point(size = .7, alpha = .3) +
scale_color_brewer(palette = "Dark2") +
labs(col = "Spatial ID") +
geom_path(data = mst, col = "black", size = 1.5) +
geom_point(data = mst, aes(col = Cluster), size = 5)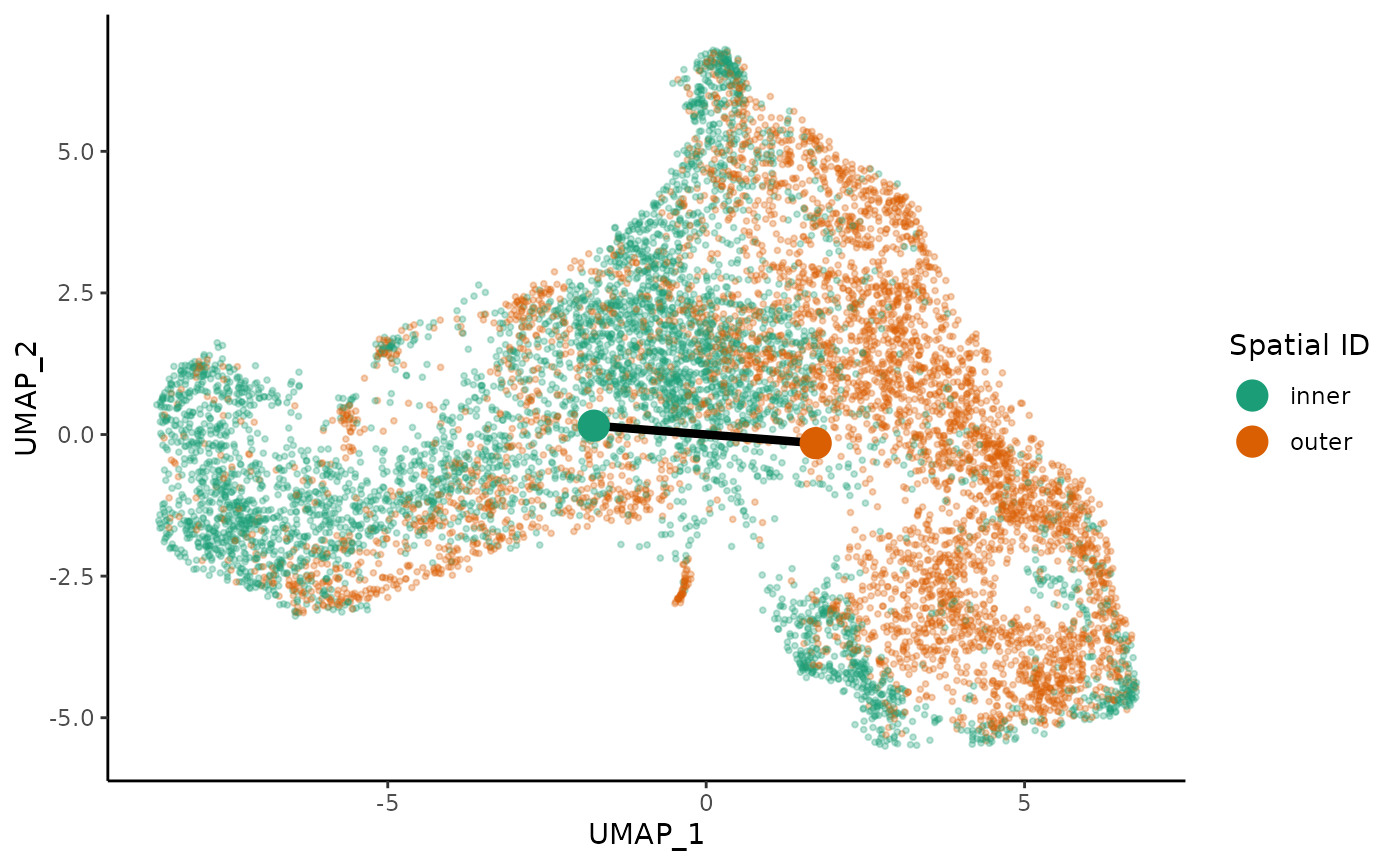
set.seed(100)
topologyTest(tgfb, conditions = tgfb$treatment_id, rep = 100)We fail to reject the null that the trajectories are different and we keep the common trajectory. This choice allows us to use the maximal amount of data in the construction of our trajectory, which should lead to more robust results than separate, potentially noisy trajectories constructed on subsets of the data. As we will see, not all cell types are necessarily present in every condition, so this approach ensures that our trajectory accounts for all cell types present in the overall data.
df$pseudotime <- slingPseudotime(tgfb)
# Plot the MST
curves <- slingCurves(tgfb, as.df = TRUE)
ggplot(df, aes(x = UMAP_1, y = UMAP_2, col = pseudotime)) +
geom_point(size = .7) +
scale_color_viridis_c() +
labs(col = "Pseudotime") +
geom_path(data = curves, col = "black", size = 1.5)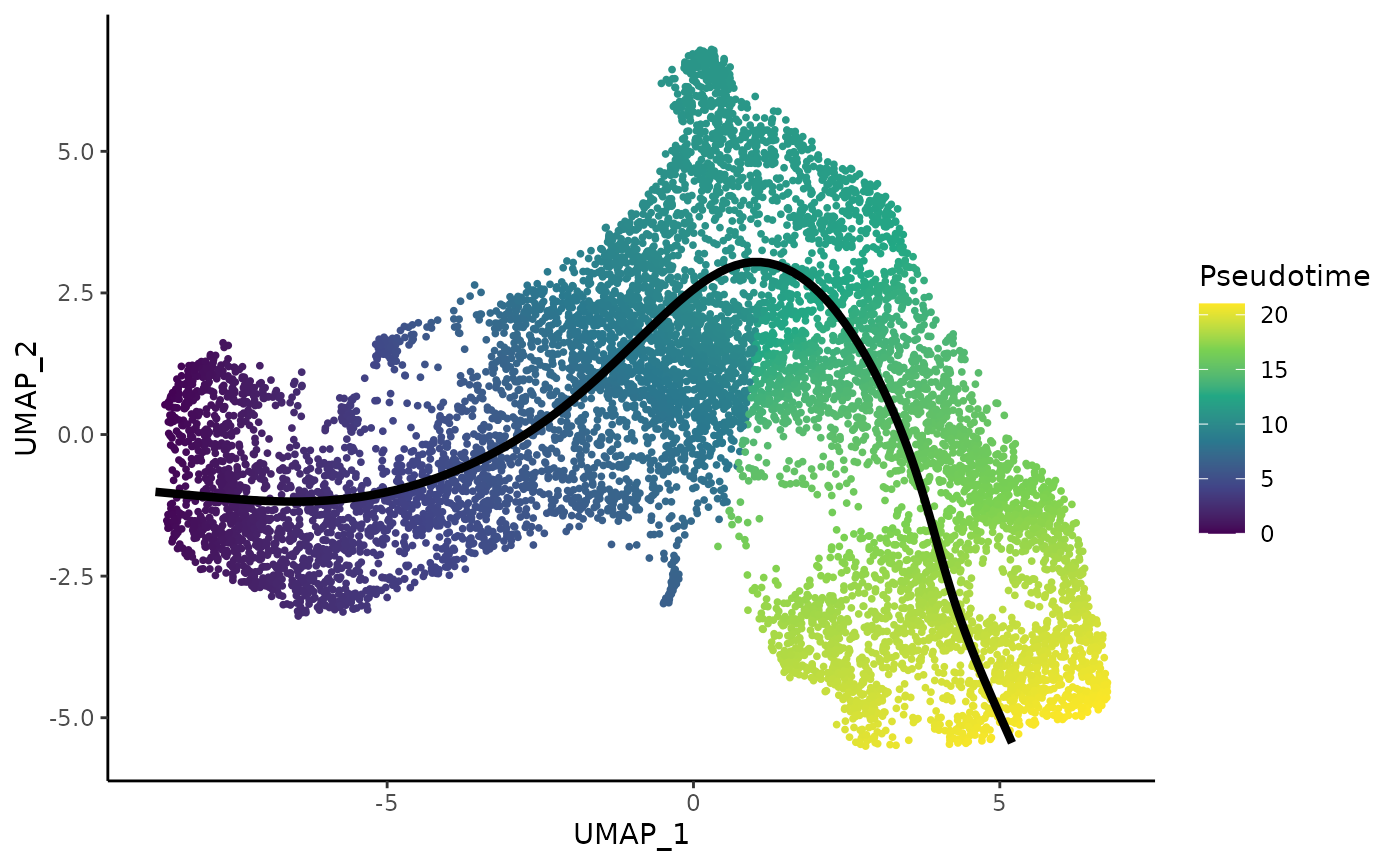
df <- as.data.frame(colData(tgfb)[,-10])
ggplot(df, aes(x = slingPseudotime_1, fill = spatial_id, col = spatial_id)) +
geom_density(alpha = .7, size = 1.5) +
scale_fill_brewer(palette = "Dark2") +
scale_color_brewer(palette = "Dark2") +
labs(fill = "Spatial ID", col = "Spatial ID", x = "Pseudotime")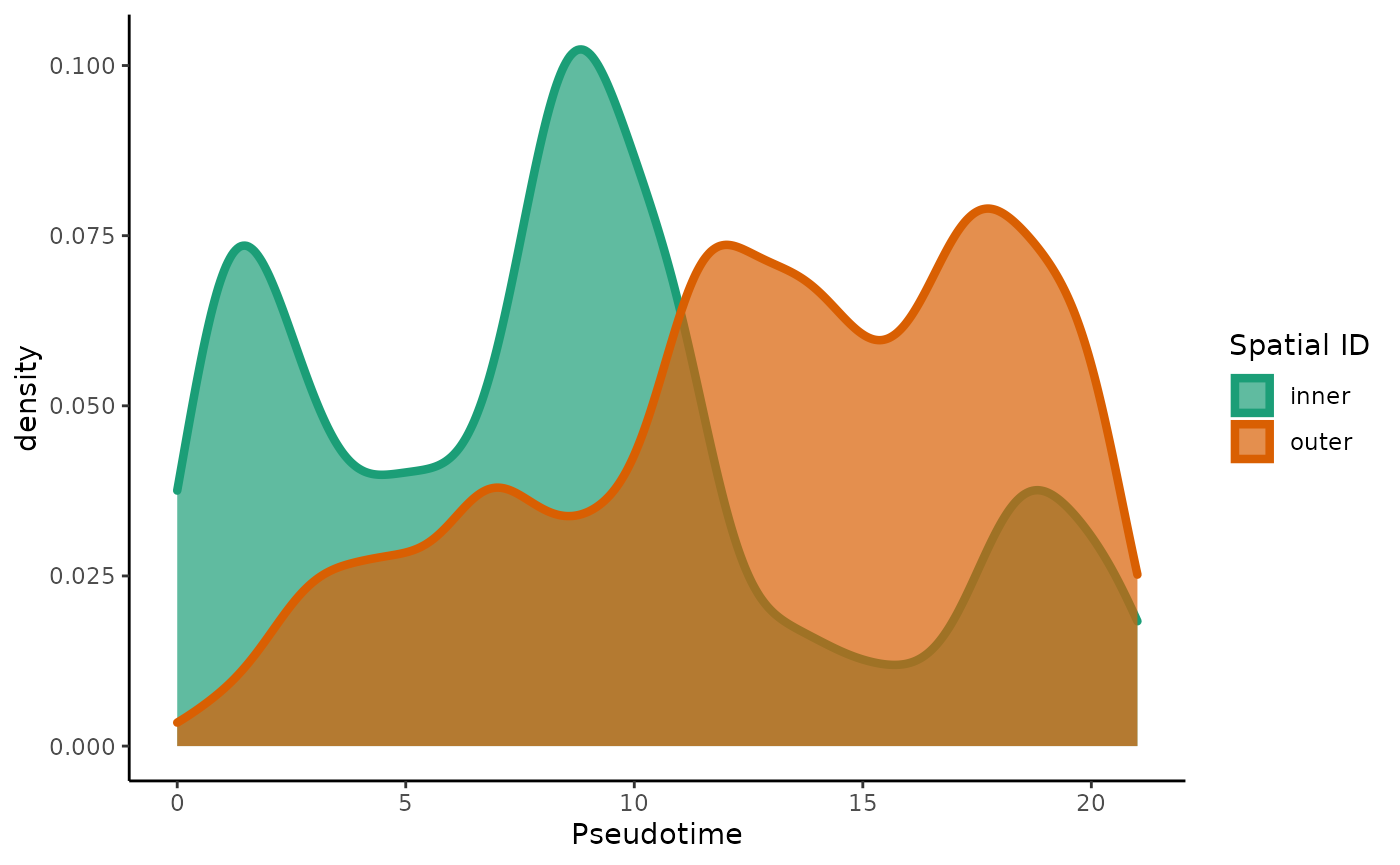
Differential progression
Now that we have ordered the cells by EMT progression, we can begin to address the main question: how is this progression affected by TGF-\(\beta\) treatment? In this section, we interpret this question as a univariate analysis of the pseudotime values between the two groups.
ggplot(df, aes(x = slingPseudotime_1, fill = treatment_id, col = treatment_id)) +
geom_density(alpha = .7, size = 1.5) +
scale_fill_brewer(palette = "Accent") +
scale_color_brewer(palette = "Accent") +
labs(fill = "Treatment ID", col = "Treatment ID", x = "PSeudotime")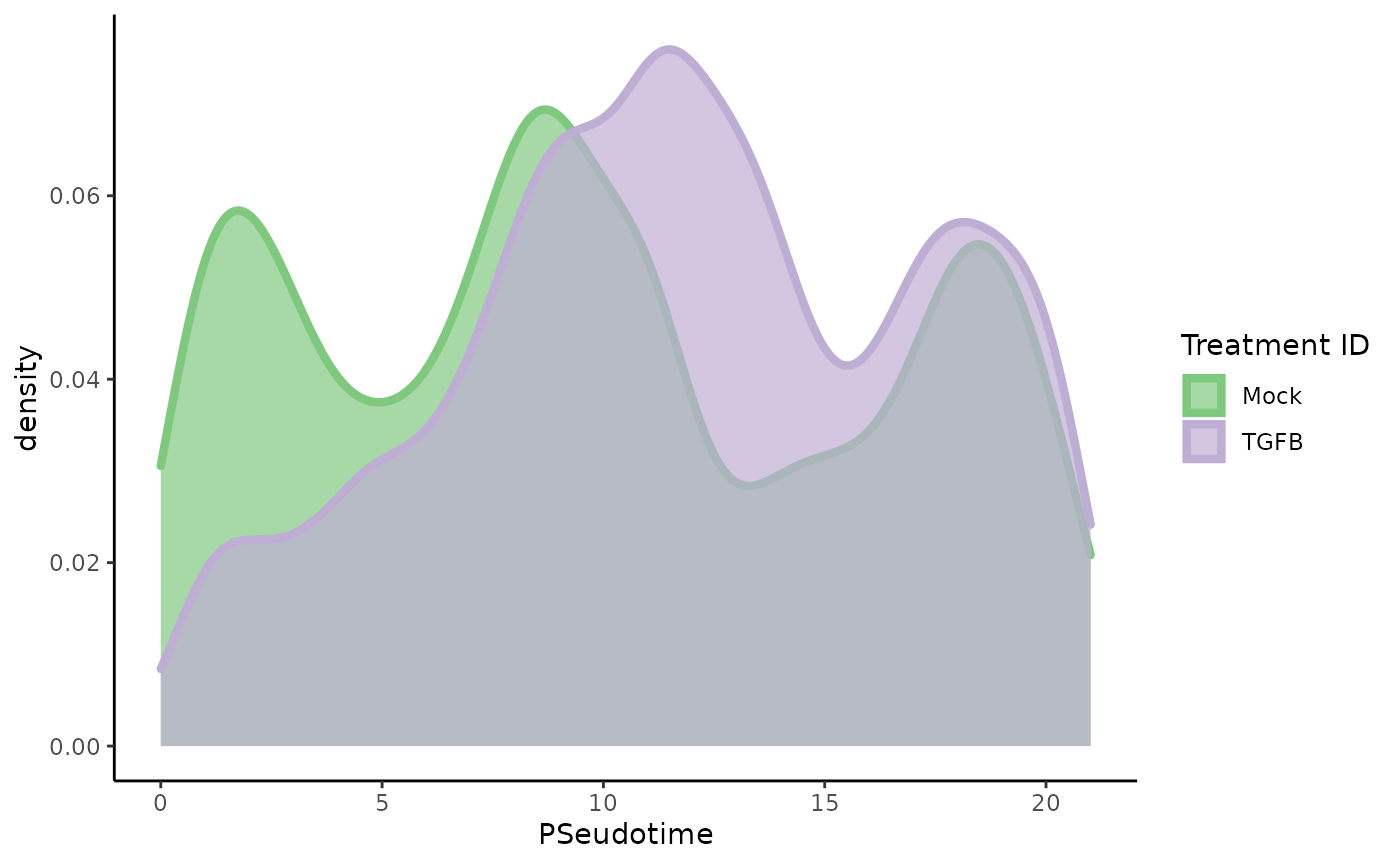
The density estimates for the two groups show a trimodal distribution for the untreated cells, but a tendency toward later pseudotime values in the TGF-\(\beta\) treated cells. The difference is striking enough that a standard T-test would likely be significant, but we are we are interested more generally in differences between the two distributions, not just the difference of means (one could imagine a scenario in which the treated group tended toward the extremes, but the means were the same). Hence, we propose a Kolmogorov-Smirnov Test to assess whether the two groups of pseudotime values are derived from the same distribution. For more info on the Kolmogorov-Smirnov Test, see here.
progressionTest(tgfb, conditions = tgfb$treatment_id)## Registered S3 method overwritten by 'cli':
## method from
## print.boxx spatstat.geom## # A tibble: 1 x 3
## lineage statistic p.value
## <chr> <dbl> <dbl>
## 1 1 0.176 2.2e-16As we might expect from the plot, this test is highly significant, so we can conclude that there are differences between the two distributions.
Differential expression
We will now proceed to discover genes whose expression is associated with the inferred trajectory. We will look for genes that (i) change in gene expression along the trajectory, and (ii) are differentially expressed between the two conditions along the trajectory. The differential expression analysis uses the Bioconductor package tradeSeq. This analysis relies on a new version of tradeSeq, which we have recently updated to allow for multiple conditions.
For each condition (i.e., control and TGF-Beta), a smooth average expression profile along pseudotime will be estimated for each gene, using a negative binomial generalized additive model (NB-GAM). Each differential expression hypothesis of interest will then be translated into testing specific features (a linear combination of the parameters) of this smoothed expression estimate. See here for more information on smoothers and the mgcv package which we are using to estimate the smoothers.
The next two paragraphs can be time-consuming so we will not run them during the workshop, however, their output is already present in the data object that was loaded at the start of this workshop. They can be easily parallelized, relying on the BiocParallel bioconductor package. See here for more details.
Select number of knots
Before we can fit these smoothed expression profiles, we need to get a sense of how complex the expression patterns are in this dataset. This is translated into selecting a number of knots for the NB-GAMs, where a higher number of knots allows for more complex expression patterns. Here, we pick \(5\) knots.
set.seed(3)
icMat <- evaluateK(counts = as.matrix(assays(tgfb)$counts),
pseudotime = colData(tgfb)$slingshot$pseudotime,
cellWeights = colData(tgfb)$slingshot$cellWeights.V1,
conditions = factor(colData(tgfb)$pheno$treatment_id),
nGenes = 300,
k = 3:7)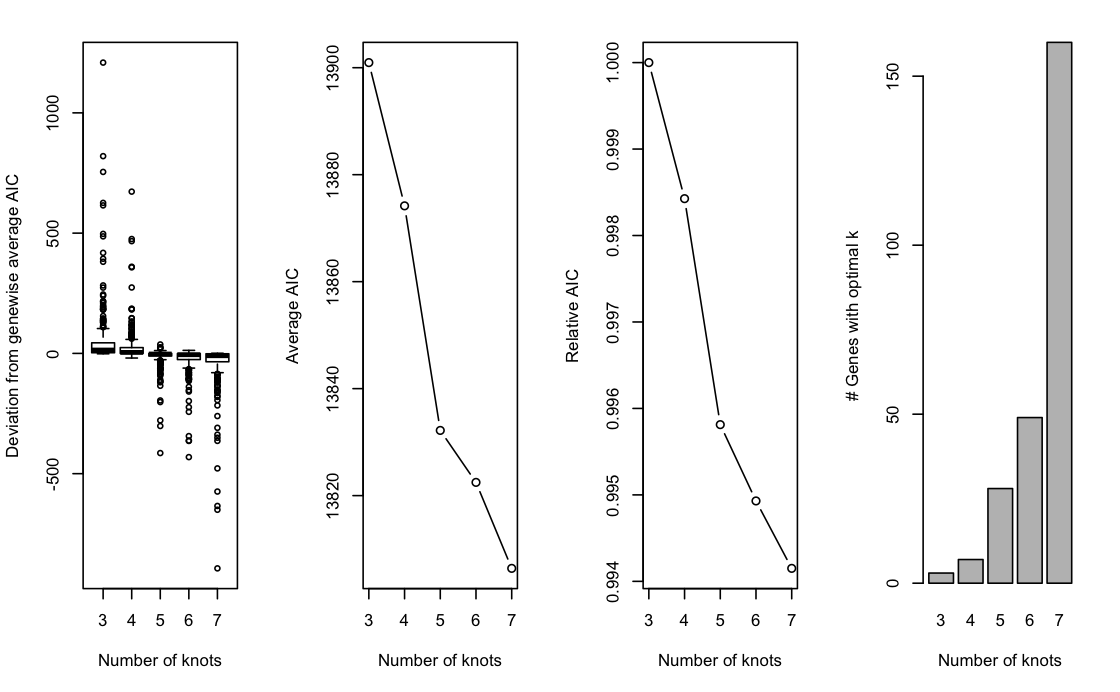
The plot above shows the graphical output from running evaluateK. The left panel shows the distribution of gene-level AIC values as compared to their average AIC over the range of k. The second and third panel plot the average AIC and relative AIC with respect to the lowest value of k (i.e., 3), respectively, as a function of k. Finally, the right panel plots the number of genes whose AIC is lowest at a particular value of k.
Choosing an appropriate value of k can be seen as analogous to choosing the number of principal components based on a scree plot: we look for an ‘elbow point’, where the decrease starts attenuating. Here, we choose k=5 to allow for flexible, yet simple, functions while limiting the computational burden. In general, we found the influence of choosing the exact value of k to be rather limited, unless k is arbitrarily small or large. In our evaluations, most datasets fall within the range of \(4\) to \(8\) knots.
Fit GAM
Next, we fit the NB-GAMs using 5 knots, based on the pseudotime and cell-level weights estimated by Slingshot. We use the conditions argument to fit separate smoothers for each condition.
set.seed(3)
metadata(tgfb)$slingshot <- SlingshotDataSet(tgfb)
tgfb <- fitGAM(tgfb, conditions = factor(colData(tgfb)$treatment_id),
nknots = 5)
mean(rowData(tgfb)$tradeSeq$converged)Assess DE along pseudotime (or pseudospace)
Note that the axis represented by the trajectory in this dataset is actually the migration of cells from the epithelium to the mesenchyme and therefore could also be looked at as a space dimension, although it is likely to be correlated with chronological time, too.
To assess significant changes in gene expression as a function of pseudotime within each lineage, we use the associationTest, which tests the null hypothesis that gene expression is not a function of pseudotime, i.e., whether the estimated smoothers are significantly varying as a function of pseudotime within each lineage. The lineages=TRUE argument specifies that we would like the results for each lineage separately, asides from the default global test, which tests for significant associations across all lineages in the trajectory simultaneously. Further, we specify a log2 fold change cut-off to test against using the l2fc argument.
On a lineage-specific basis, there are over twice as much DE genes in the mock lineage (2398) as compared to the TGFB lineage (1013). Many of the DE genes in the TGFB condition are also DE in the mock condition, around 80%.
The authors of the original paper found \(1105\) DE genes for the mock condition on a FDR level of \(1e-10\) and a cut-off of 1 on the absolute value of the log2 fold change.
rowData(tgfb)$assocRes <- associationTest(tgfb, lineages = TRUE, l2fc = log2(2))
library(tradeSeq)
assocRes <- rowData(tgfb)$assocRes
mockGenes <- rownames(assocRes)[
which(p.adjust(assocRes$pvalue_lineage1_conditionMock, "fdr") <= 0.05)
]
tgfbGenes <- rownames(assocRes)[
which(p.adjust(assocRes$pvalue_lineage1_conditionTGFB, "fdr") <= 0.05)
]
length(mockGenes)## [1] 2399
length(tgfbGenes)## [1] 1013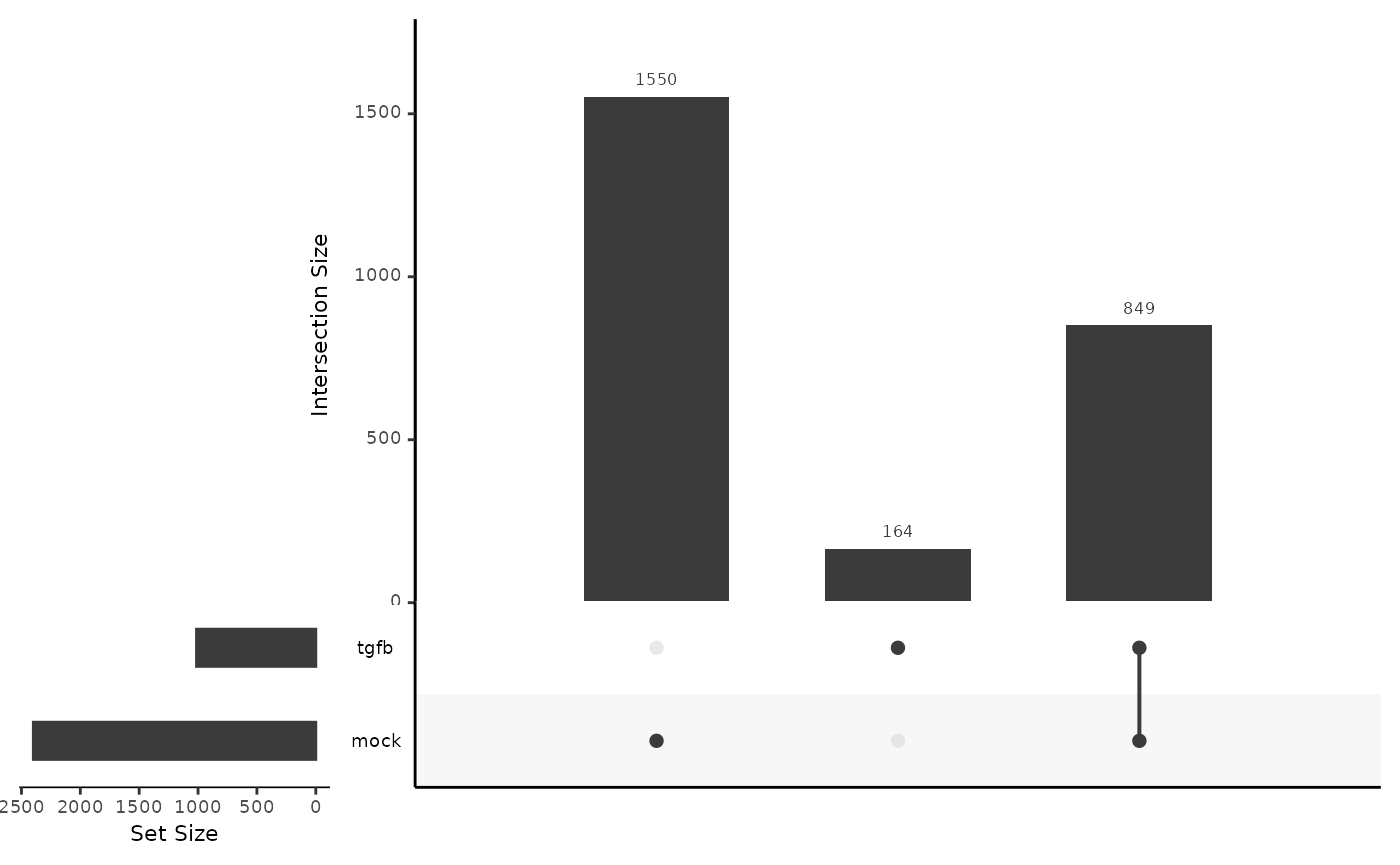
Visualization of DE genes
Below we visualize and cluster the genes whose expression vary over pseudotime, using the smoothed expression patterns As was also observed in the original manuscript, genes are mainly upregulated at the start- or endpoints of the lineage.
### based on mean smoother
yhatSmooth <- predictSmooth(tgfb, gene = mockGenes, nPoints = 50, tidy = FALSE)
yhatSmoothScaled <- t(apply(yhatSmooth,1, scales::rescale))
heatSmooth <- pheatmap(yhatSmoothScaled[, 1:50],
cluster_cols = FALSE,
show_rownames = FALSE,
show_colnames = FALSE)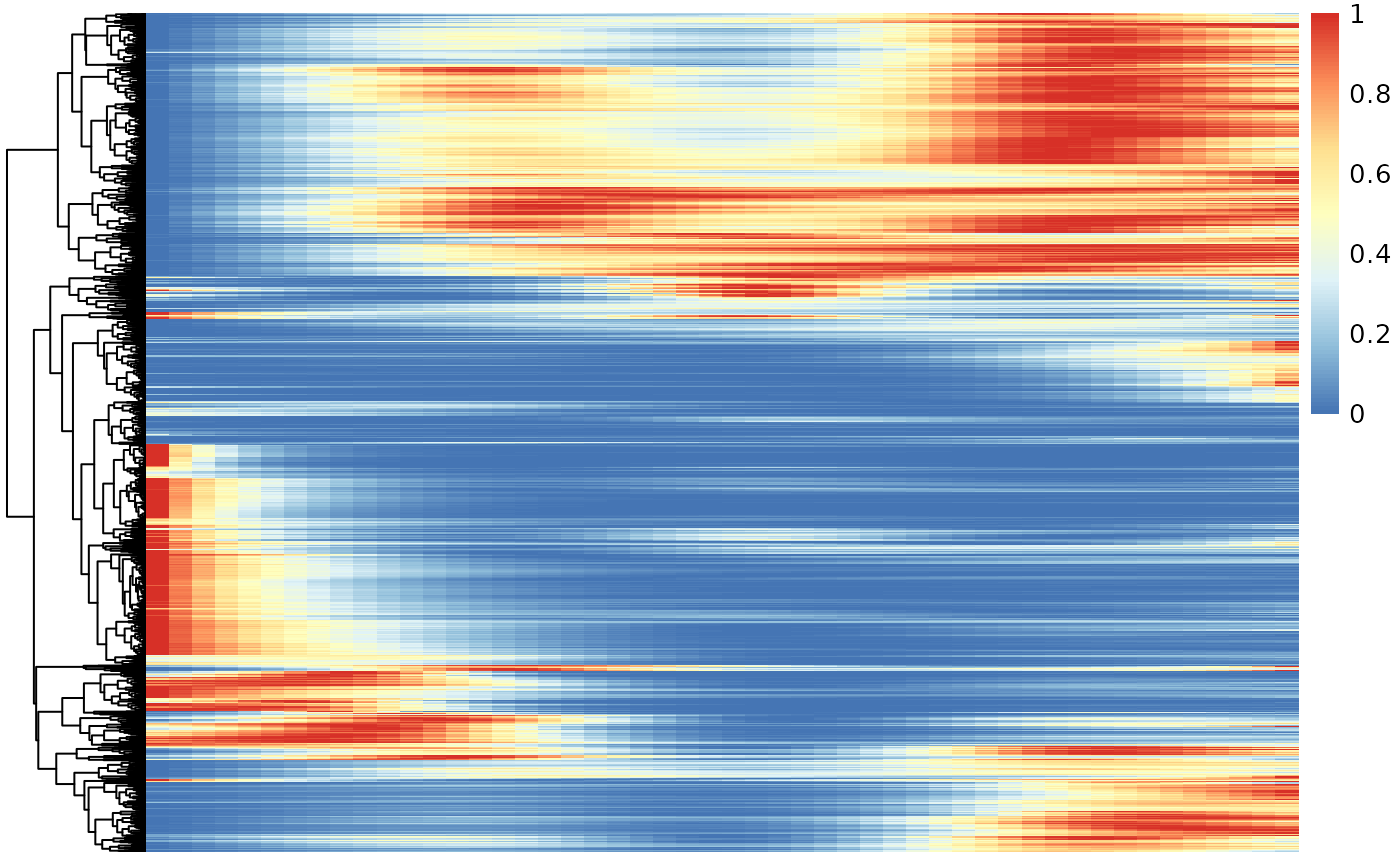
## the hierarchical trees constructed here, can also be used for
## clustering of the genes according to their average expression pattern.
cl <- sort(cutree(heatSmooth$tree_row, k = 6))
table(cl)## cl
## 1 2 3 4 5 6
## 104 752 215 1010 300 18
conditions <- colData(tgfb)$treatment_id
pt1 <- tgfb$slingPseudotime_1
### based on fitted values (plotting takes a while to run)
yhatCell <- predictCells(tgfb, gene = mockGenes)
yhatCellMock <- yhatCell[, conditions == "Mock"]
# order according to pseudotime
ooMock <- order(pt1[conditions == "Mock"], decreasing = FALSE)
yhatCellMock <- yhatCellMock[, ooMock] %>%
log1p()
yhatCellMock <- t(apply(yhatCellMock,1, scales::rescale))
pheatmap(yhatCellMock,
cluster_cols = FALSE,
show_rownames = FALSE, show_colnames = FALSE
)Gene set enrichment analysis on genes from the Mock condition
Gene set enrichment analysis on the DE genes within the mock condition confirms the biology on epithelial cell differentiation.
## C5 category is according to gene ontology grouping: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4707969/pdf/nihms-743907.pdf
geneSets <- msigdbr(species = "Mus musculus", category = "C5", subcategory = "BP")
### filter background to only include genes that we assessed.
geneSets$gene_symbol <- toupper(geneSets$gene_symbol)
geneSets <- geneSets[geneSets$gene_symbol %in% names(tgfb),]
m_list <- geneSets %>% split(x = .$gene_symbol, f = .$gs_name)
stats <- assocRes$waldStat_lineage1_conditionMock
names(stats) <- rownames(assocRes)
eaRes <- fgsea(pathways = m_list, stats = stats, nperm = 5e4, minSize = 10)## Warning in fgsea(pathways = m_list, stats = stats, nperm = 50000, minSize = 10):
## You are trying to run fgseaSimple. It is recommended to use fgseaMultilevel. To
## run fgseaMultilevel, you need to remove the nperm argument in the fgsea function
## call.## Warning in preparePathwaysAndStats(pathways, stats, minSize, maxSize, gseaParam, : There are ties in the preranked stats (0.01% of the list).
## The order of those tied genes will be arbitrary, which may produce unexpected results.| pathway | pval | padj |
|---|---|---|
| GOBP_CELL_CYCLE | 0.00002 | 0.0644320 |
| GOBP_EPITHELIAL_CELL_DIFFERENTIATION | 0.00006 | 0.0644320 |
| GOBP_EPITHELIUM_DEVELOPMENT | 0.00006 | 0.0644320 |
| GOBP_MITOTIC_NUCLEAR_DIVISION | 0.00008 | 0.0644320 |
| GOBP_NEGATIVE_REGULATION_OF_CELLULAR_COMPONENT_ORGANIZATION | 0.00010 | 0.0644320 |
| GOBP_ORGANELLE_FISSION | 0.00010 | 0.0644320 |
| GOBP_EPIDERMIS_DEVELOPMENT | 0.00014 | 0.0676536 |
| GOBP_MITOTIC_CELL_CYCLE | 0.00014 | 0.0676536 |
| GOBP_SKIN_DEVELOPMENT | 0.00020 | 0.0850503 |
| GOBP_CHROMOSOME_ORGANIZATION | 0.00022 | 0.0850503 |
| GOBP_PROTEOLYSIS | 0.00030 | 0.0966481 |
| GOBP_REGULATION_OF_CHROMOSOME_ORGANIZATION | 0.00030 | 0.0966481 |
| GOBP_CELL_CYCLE_PROCESS | 0.00044 | 0.1308466 |
| GOBP_CHROMOSOME_SEGREGATION | 0.00058 | 0.1494823 |
| GOBP_EPIDERMAL_CELL_DIFFERENTIATION | 0.00058 | 0.1494823 |
| GOBP_POSITIVE_REGULATION_OF_DENDRITE_MORPHOGENESIS | 0.00064 | 0.1546369 |
| GOBP_CELL_DIVISION | 0.00074 | 0.1546369 |
| GOBP_POSITIVE_REGULATION_OF_JUN_KINASE_ACTIVITY | 0.00074 | 0.1546369 |
| GOBP_DEFENSE_RESPONSE_TO_OTHER_ORGANISM | 0.00078 | 0.1546369 |
| GOBP_NEGATIVE_REGULATION_OF_ORGANELLE_ORGANIZATION | 0.00084 | 0.1546369 |
Differential expression between conditions
In the following sections, we will investigate differential expression for each gene, between the two conditions.
We will first make exploratory data analysis visualizations to take a look at the expression patterns of genes that were also discussed in the original manuscript. The paper mentions that CDH1 and CRB3 should be expressed in similar kinetics. Note that the lower slope of CDH1 is also observed in the paper.
plotSmoothers(tgfb, assays(tgfb)$counts, gene = "CDH1", alpha = 1, border = TRUE) + ggtitle("CDH1")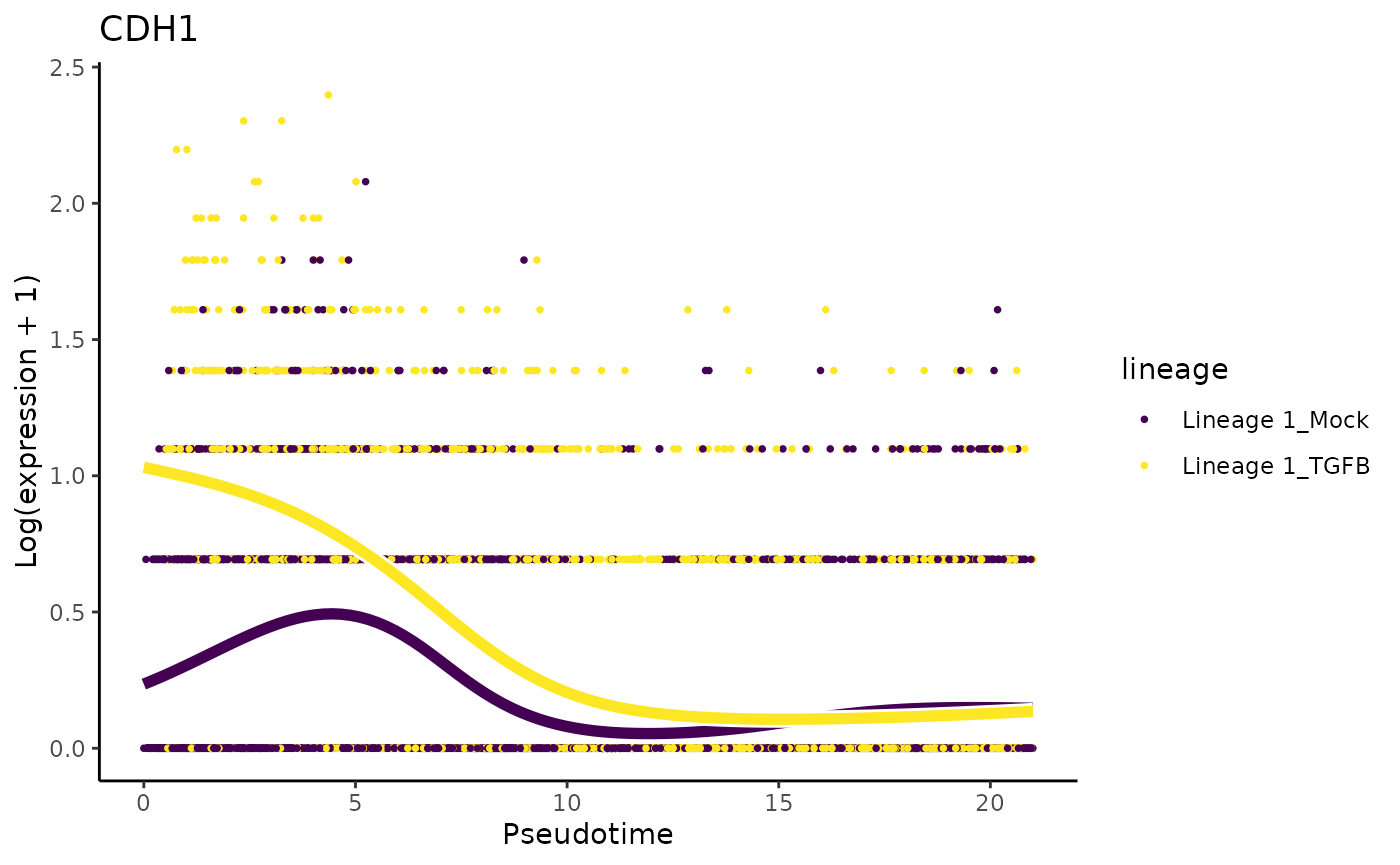
plotSmoothers(tgfb, assays(tgfb)$counts, gene = "CRB3", alpha = 1, border = TRUE) + ggtitle("CRB3")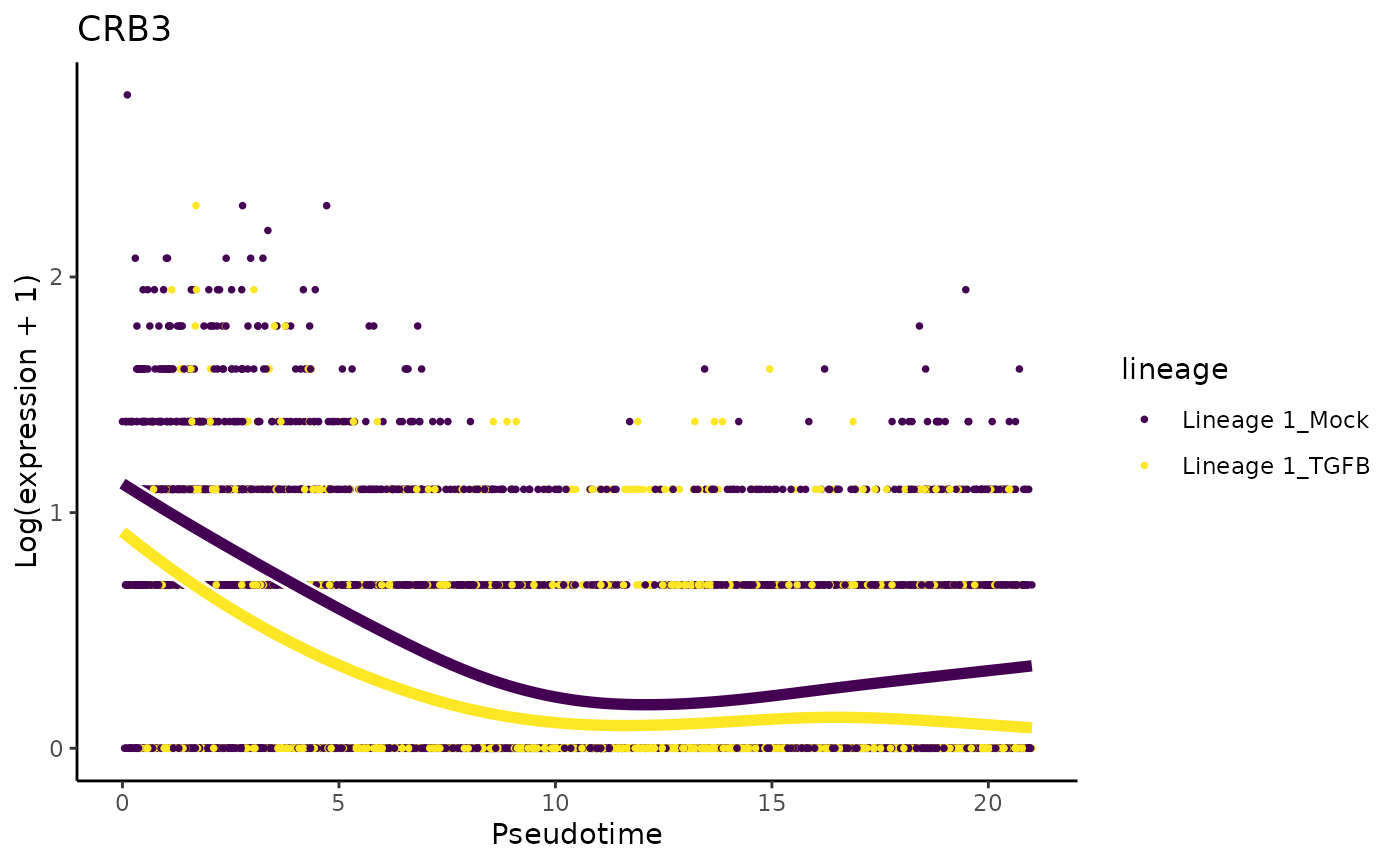
They also mention that ‘only cells treated with TGF-Beta and positioned at the outer extreme of the trajectory expressed robust levels of FN1 and CDH2’.
plotSmoothers(tgfb, assays(tgfb)$counts, gene = "FN1", alpha = 1, border = TRUE) + ggtitle("FN1")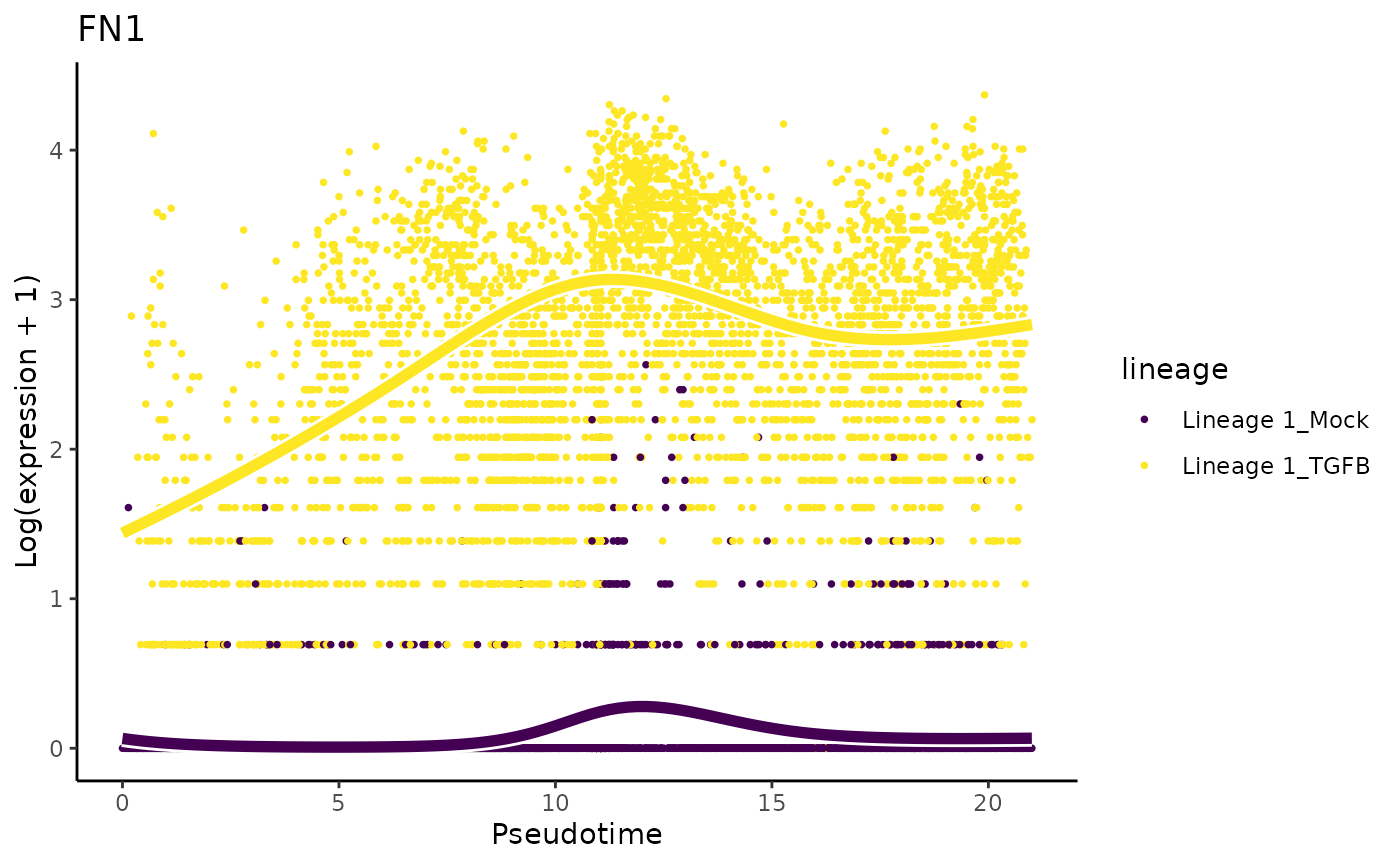
plotSmoothers(tgfb, assays(tgfb)$counts, gene = "CDH2", alpha = 1, border = TRUE) + ggtitle("CDH2")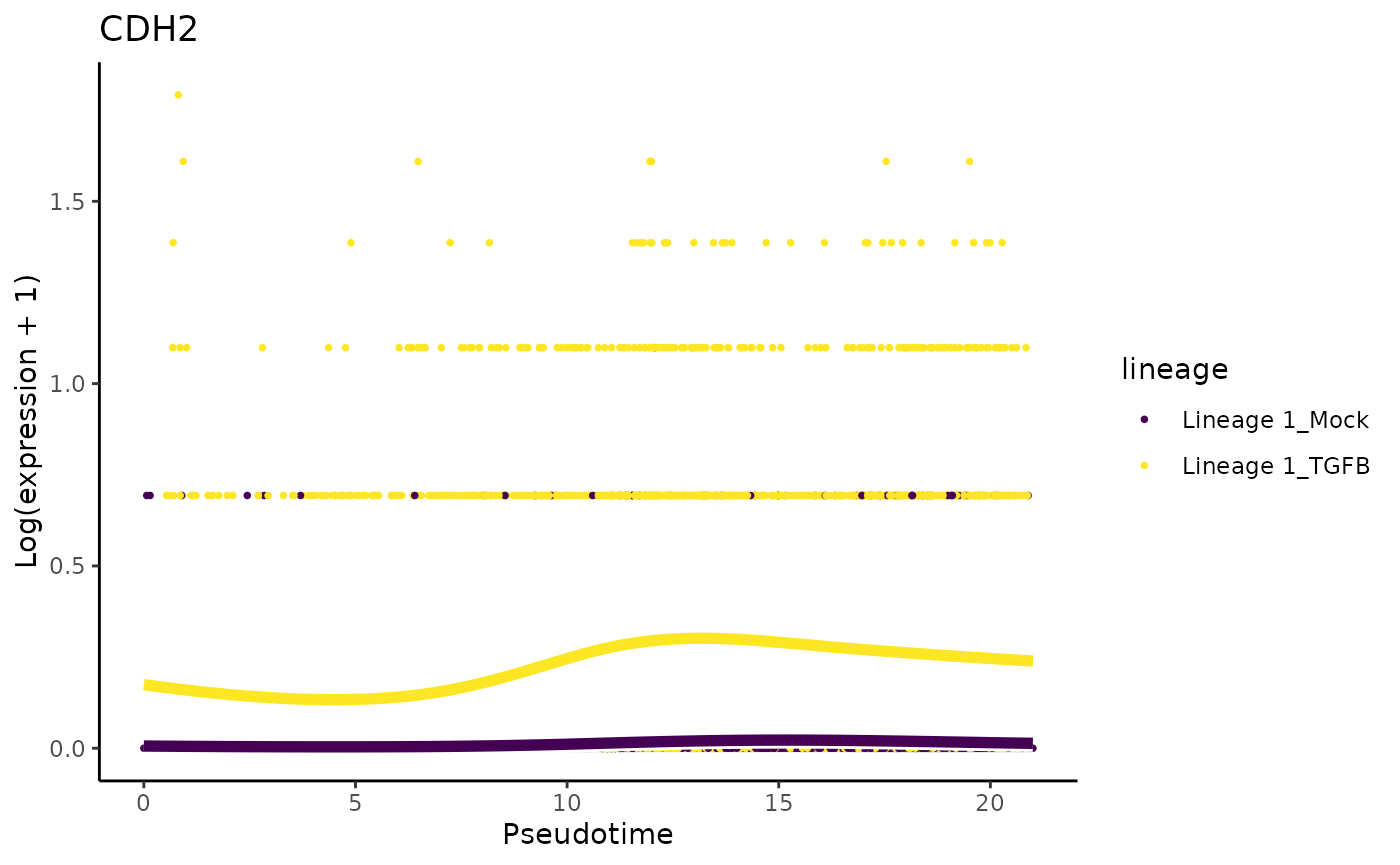
Differential expression analysis
To test differential expression between conditions, we use the conditionTest function implemented in tradeSeq. This function tests the null hypothesis that genes have identical expression patterns in each condition. We discover \(1993\) genes that are DE with a fold change higher than \(2\) or lower than \(1/2\).
condRes <- conditionTest(tgfb, l2fc = log2(2))
condRes$padj <- p.adjust(condRes$pvalue, "fdr")
mean(condRes$padj <= 0.05, na.rm = TRUE)## [1] 0.1889995
sum(condRes$padj <= 0.05, na.rm = TRUE)## [1] 1993Visualize most and least significant gene
# plot genes
oo <- order(condRes$waldStat, decreasing = TRUE)
# most significant gene
plotSmoothers(tgfb, assays(tgfb)$counts,
gene = rownames(assays(tgfb)$counts)[oo[1]],
alpha = 1, border = TRUE)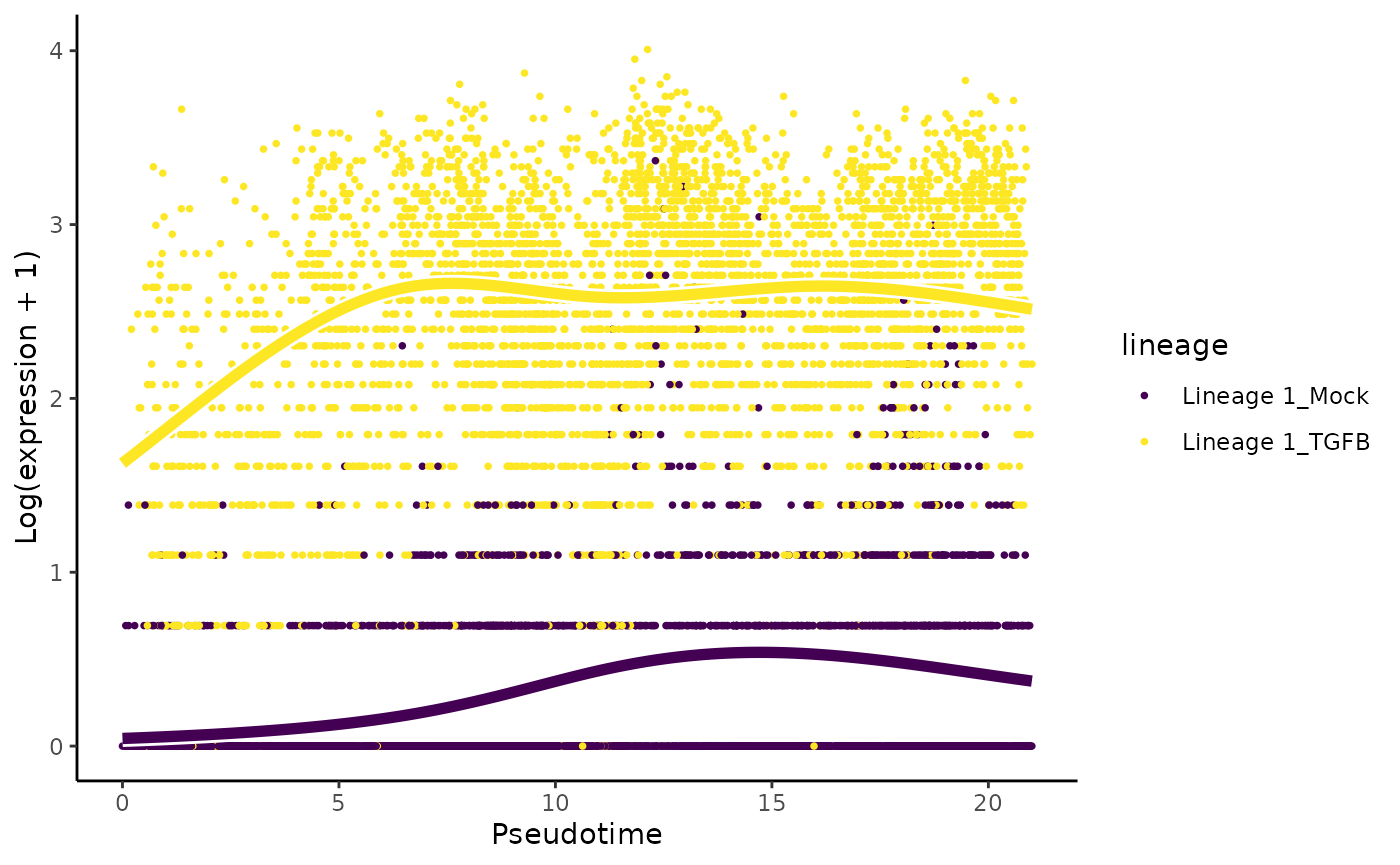
# least significant gene
plotSmoothers(tgfb, assays(tgfb)$counts,
gene = rownames(assays(tgfb)$counts)[oo[nrow(tgfb)]],
alpha = 1, border = TRUE)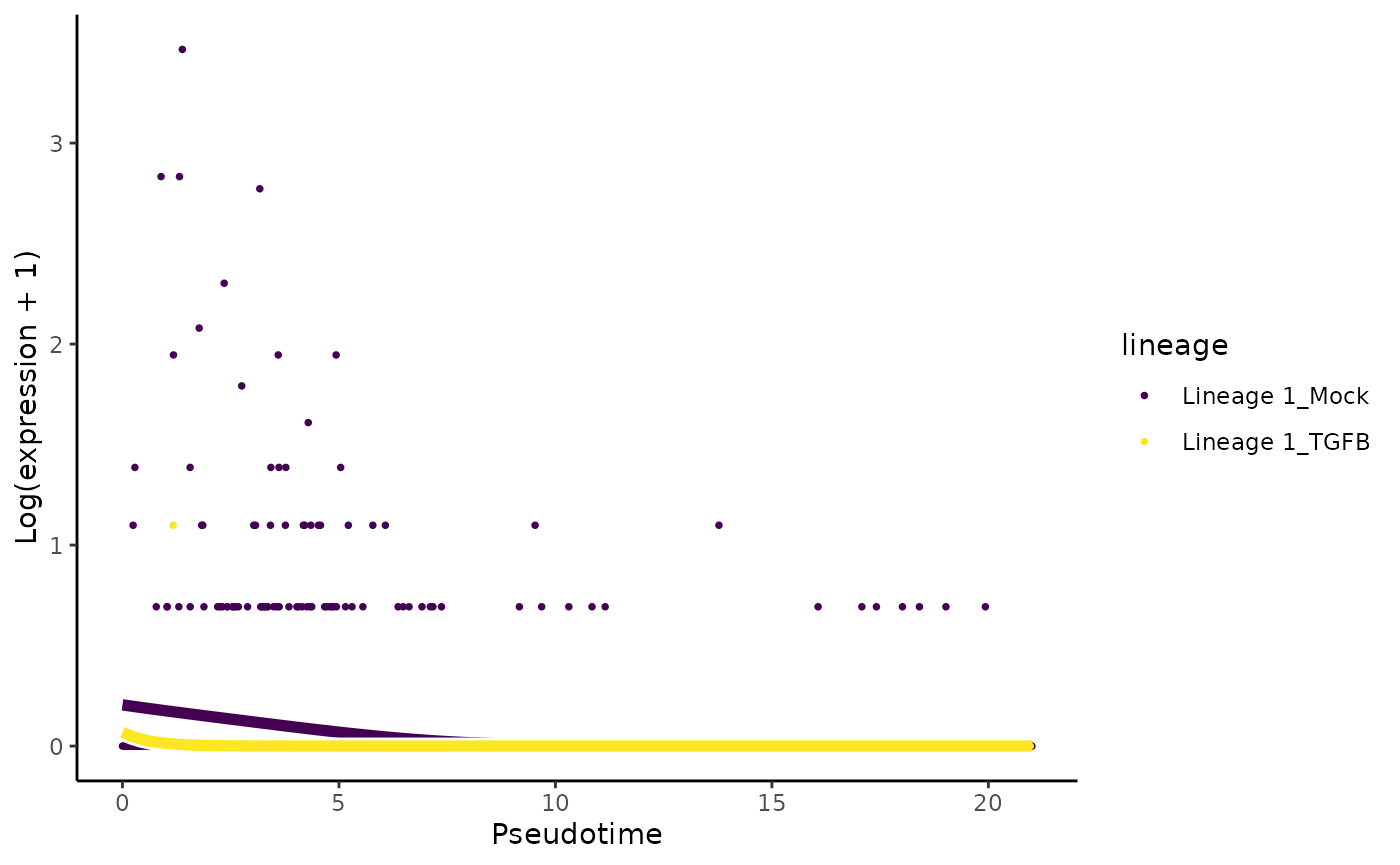
Heatmaps of genes DE between conditions
Below we show heatmaps of the genes DE between conditions. The DE genes in the heatmaps are ordered according to a hierarchical clustering on the TGF-Beta condition.
### based on mean smoother
yhatSmooth <- predictSmooth(tgfb, gene = conditionGenes, nPoints = 50, tidy = FALSE) %>%
log1p()
yhatSmoothScaled <- t(apply(yhatSmooth,1, scales::rescale))
heatSmooth_TGF <- pheatmap(yhatSmoothScaled[, 51:100],
cluster_cols = FALSE,
show_rownames = FALSE, show_colnames = FALSE, main = "TGF-Beta", legend = FALSE,
silent = TRUE
)
matchingHeatmap_mock <- pheatmap(yhatSmoothScaled[heatSmooth_TGF$tree_row$order, 1:50],
cluster_cols = FALSE, cluster_rows = FALSE,
show_rownames = FALSE, show_colnames = FALSE, main = "Mock",
legend = FALSE, silent = TRUE
)
plot_grid(heatSmooth_TGF[[4]], matchingHeatmap_mock[[4]], ncol = 2)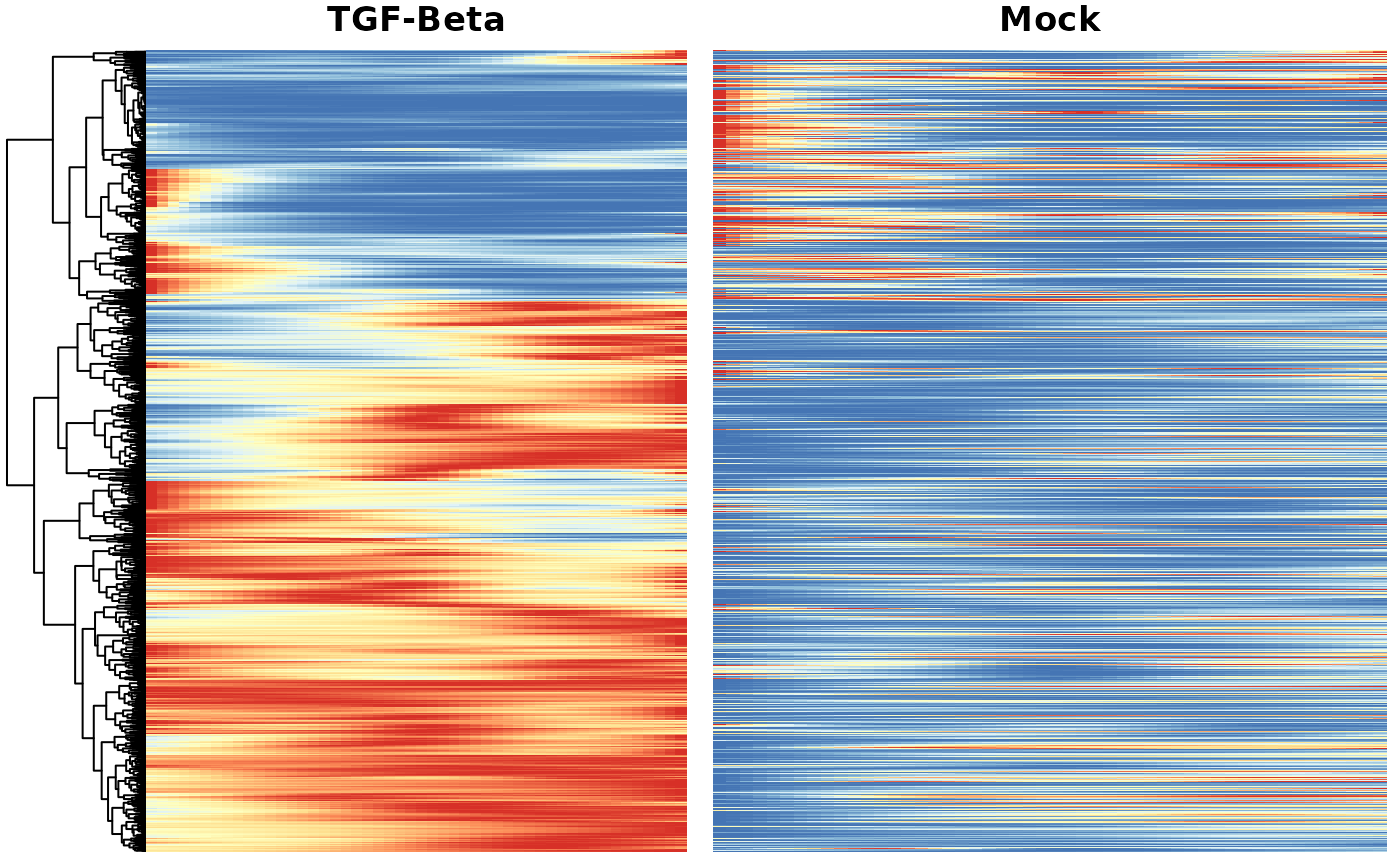
Gene set enrichment analysis
Gene set enrichment analysis on genes that are differentially expressed between conditions finds evidence for cell motility, cell junctions/adhesion and gastrulation. The original paper also focuses on the KRAS signaling pathway, which induces cell migration, amongst others. Other related processes include morphogenesis, gastrulation and cell adhesion.
statsCond <- condRes$waldStat
names(statsCond) <- rownames(condRes)
eaRes <- fgsea(pathways = m_list, stats = statsCond, nperm = 5e4, minSize = 10)## Warning in fgsea(pathways = m_list, stats = statsCond, nperm = 50000,
## minSize = 10): You are trying to run fgseaSimple. It is recommended to use
## fgseaMultilevel. To run fgseaMultilevel, you need to remove the nperm argument
## in the fgsea function call.## Warning in preparePathwaysAndStats(pathways, stats, minSize, maxSize, gseaParam, : There are ties in the preranked stats (0.03% of the list).
## The order of those tied genes will be arbitrary, which may produce unexpected results.| pathway | pval | padj |
|---|---|---|
| GOBP_BIOLOGICAL_ADHESION | 0.0000200 | 0.0258062 |
| GOBP_CELL_MIGRATION | 0.0000200 | 0.0258062 |
| GOBP_LOCOMOTION | 0.0000200 | 0.0258062 |
| GOBP_ANATOMICAL_STRUCTURE_FORMATION_INVOLVED_IN_MORPHOGENESIS | 0.0000400 | 0.0387092 |
| GOBP_REGULATION_OF_CELL_ADHESION | 0.0001000 | 0.0774185 |
| GOBP_CELL_POPULATION_PROLIFERATION | 0.0001400 | 0.0903215 |
| GOBP_REGULATION_OF_MITOCHONDRIAL_GENE_EXPRESSION | 0.0004600 | 0.2543749 |
| GOBP_TRANSCRIPTION_BY_RNA_POLYMERASE_III | 0.0006400 | 0.3096738 |
| GOBP_VASCULATURE_DEVELOPMENT | 0.0008200 | 0.3225769 |
| GOBP_REGULATION_OF_CELLULAR_COMPONENT_MOVEMENT | 0.0008800 | 0.3225769 |
| GOBP_EXTERNAL_ENCAPSULATING_STRUCTURE_ORGANIZATION | 0.0009200 | 0.3225769 |
| GOBP_TUBE_DEVELOPMENT | 0.0010000 | 0.3225769 |
| GOBP_CELL_CELL_ADHESION | 0.0012600 | 0.3303187 |
| GOBP_MITOCHONDRIAL_RNA_METABOLIC_PROCESS | 0.0012600 | 0.3303187 |
| GOBP_CIRCULATORY_SYSTEM_DEVELOPMENT | 0.0012800 | 0.3303187 |
| GOBP_BLOOD_VESSEL_MORPHOGENESIS | 0.0014800 | 0.3381964 |
| GOBP_N_TERMINAL_PROTEIN_AMINO_ACID_MODIFICATION | 0.0015600 | 0.3381964 |
| GOBP_TAXIS | 0.0015800 | 0.3381964 |
| GOBP_CELL_JUNCTION_ASSEMBLY | 0.0016600 | 0.3381964 |
| GOBP_MOTOR_NEURON_AXON_GUIDANCE | 0.0018603 | 0.3465397 |
Final notes
A compiled version of the vignette is available on the workshop website.
If you have questions that you could not ask during the workshop, feel free to open an issue on the github repository here.
## R version 4.1.0 (2021-05-18)
## Platform: x86_64-pc-linux-gnu (64-bit)
## Running under: Ubuntu 20.04.2 LTS
##
## Matrix products: default
## BLAS/LAPACK: /usr/lib/x86_64-linux-gnu/openblas-pthread/libopenblasp-r0.3.8.so
##
## locale:
## [1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
## [3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
## [5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=C
## [7] LC_PAPER=en_US.UTF-8 LC_NAME=C
## [9] LC_ADDRESS=C LC_TELEPHONE=C
## [11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
##
## attached base packages:
## [1] stats4 stats graphics grDevices utils datasets methods
## [8] base
##
## other attached packages:
## [1] cowplot_1.1.1 tradeSeq_1.7.03
## [3] gridExtra_2.3 ggplot2_3.3.5
## [5] fgsea_1.19.0 msigdbr_7.4.1
## [7] pheatmap_1.0.12 UpSetR_1.4.0
## [9] viridis_0.6.1 viridisLite_0.4.0
## [11] scales_1.1.1 RColorBrewer_1.1-2
## [13] condiments_1.1.02 dplyr_1.0.7
## [15] slingshot_2.1.0 TrajectoryUtils_1.1.0
## [17] SingleCellExperiment_1.15.1 SummarizedExperiment_1.23.1
## [19] Biobase_2.53.0 GenomicRanges_1.45.0
## [21] GenomeInfoDb_1.29.3 IRanges_2.27.0
## [23] S4Vectors_0.31.0 BiocGenerics_0.39.1
## [25] MatrixGenerics_1.5.1 matrixStats_0.59.0
## [27] princurve_2.1.6 knitr_1.33
##
## loaded via a namespace (and not attached):
## [1] fastmatch_1.1-0 systemfonts_1.0.2
## [3] plyr_1.8.6 igraph_1.2.6
## [5] splines_4.1.0 BiocParallel_1.27.0
## [7] digest_0.6.27 foreach_1.5.1
## [9] htmltools_0.5.1.1 fansi_0.5.0
## [11] magrittr_2.0.1 memoise_2.0.0
## [13] tensor_1.5 limma_3.49.1
## [15] recipes_0.1.16 gower_0.2.2
## [17] pkgdown_1.6.1 spatstat.sparse_2.0-0
## [19] colorspace_2.0-2 textshaping_0.3.5
## [21] xfun_0.24 crayon_1.4.1
## [23] RCurl_1.98-1.3 spatstat_2.2-0
## [25] spatstat.data_2.1-0 survival_3.2-11
## [27] iterators_1.0.13 glue_1.4.2
## [29] polyclip_1.10-0 gtable_0.3.0
## [31] ipred_0.9-11 zlibbioc_1.39.0
## [33] XVector_0.33.0 DelayedArray_0.19.1
## [35] Ecume_0.9.1 kernlab_0.9-29
## [37] abind_1.4-5 edgeR_3.35.0
## [39] Rcpp_1.0.6 spatstat.core_2.2-0
## [41] proxy_0.4-26 lava_1.6.9
## [43] prodlim_2019.11.13 ellipsis_0.3.2
## [45] pkgconfig_2.0.3 farver_2.1.0
## [47] nnet_7.3-16 deldir_0.2-10
## [49] locfit_1.5-9.4 utf8_1.2.1
## [51] caret_6.0-88 tidyselect_1.1.1
## [53] labeling_0.4.2 rlang_0.4.11
## [55] reshape2_1.4.4 munsell_0.5.0
## [57] tools_4.1.0 cachem_1.0.5
## [59] cli_3.0.0 generics_0.1.0
## [61] evaluate_0.14 stringr_1.4.0
## [63] fastmap_1.1.0 yaml_2.2.1
## [65] ragg_1.1.3 goftest_1.2-2
## [67] ModelMetrics_1.2.2.2 transport_0.12-2
## [69] babelgene_21.4 fs_1.5.0
## [71] purrr_0.3.4 RANN_2.6.1
## [73] sparseMatrixStats_1.5.0 pbapply_1.4-3
## [75] nlme_3.1-152 compiler_4.1.0
## [77] e1071_1.7-7 spatstat.utils_2.2-0
## [79] spatstat.linnet_2.2-1 tibble_3.1.2
## [81] stringi_1.6.2 highr_0.9
## [83] desc_1.3.0 lattice_0.20-44
## [85] Matrix_1.3-4 vctrs_0.3.8
## [87] pillar_1.6.1 lifecycle_1.0.0
## [89] spatstat.geom_2.2-0 data.table_1.14.0
## [91] bitops_1.0-7 R6_2.5.0
## [93] codetools_0.2-18 MASS_7.3-54
## [95] rprojroot_2.0.2 withr_2.4.2
## [97] GenomeInfoDbData_1.2.6 mgcv_1.8-36
## [99] parallel_4.1.0 grid_4.1.0
## [101] rpart_4.1-15 timeDate_3043.102
## [103] class_7.3-19 rmarkdown_2.9
## [105] DelayedMatrixStats_1.15.0 pROC_1.17.0.1
## [107] lubridate_1.7.10